The CherryPy web framework (for Python) have some great features, like automatic url-to-method mapping. But it uses some “toy code” that makes it hard to handle for some Python editors. PyPe is a Python editor written in Python, so it’s easy to modify for a Python programmer. Let’s modify the builtin class browser so it handles CherryPy files perfectly. To follow this guide you should have PyPe installed (I have some problems with version 1.9.3, but 1.9.2 works perfectly) and a CherryClass (any .cpy file from the CherryPy distribution up to the current 0.10) or this file. Future versions of CherryPy will use only Regular Python code so unfortunately this guide will not be so useful within a few months. Let’s first take a look at the PyPe class browser’s presentation of a CherryClass :
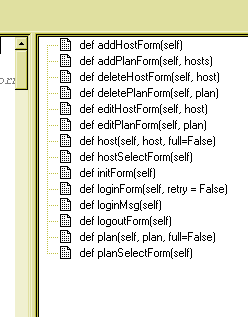
As you see, it only shows the functions. We want it to create a browsable tree with the CherryClass at the top level, sections as children of the CherryClass, and functions as children of the sections.
First, CherryPy uses an extension of Python classes called CherryClasses, identified by the keyword CherryClass. CherryClasses are divided into multiple sections called variable, aspect, mask, view and function. We need to make PyPe code parser aware of these keywords. The function we must modify is called fun and is a method of the function fast_parser in the parsers.py file. The fun function starts at line 35 (for PyPy 1.9.3). The relevant code is from line 100.
if ls[:4] == 'def ':
fun('def ', line, ls, line_no, stk)
elif ls[:6] == 'class ':
fun('class ', line, ls, line_no, stk)
elif ls[:1] == '#':
a = ls.lower().find('todo:')
if a+1:
todo.append((line_no, ls.count('!'), ls[a+5:].strip()))
You can see that it identifies class and function declarations and “todo” comments (a PyPe special feature). We just need to make it aware of the special CherryPy keywords. We also need 2 small hacks to make CherryClass sections reside within the CherryClass in the tree (because these are not indented) and to identify them as sections. The code to add, preferably after
elif ls[:6] == 'class ':
fun('class ', line, ls, line_no, stk)
is this:
elif ls[:12] == 'CherryClass ':
fun('CherryClass ', line, ls, line_no, stk)
elif ls[:9] == 'variable:':
ls = "section variable:"
line = " " + ls
fun('section ', line, ls, line_no, stk)
elif ls[:5] == 'mask:':
ls = "section mask:"
line = " " + ls
fun('section ', line, ls, line_no, stk)
elif ls[:5] == 'view:':
ls = "section view:"
line = " " + ls
fun('section ', line, ls, line_no, stk)
elif ls[:9] == 'function:':
ls = "section function:"
line = " " + ls
fun('section ', line, ls, line_no, stk)
elif ls[:7] == 'aspect:':
ls = "section aspect:"
line = " " + ls
fun('section ', line, ls, line_no, stk)
The 2 hacks are ls = "section keyword:" to add the section keyword before the type of section, and line = " " + ls to artificially indent the section identifier lines with one space. If you are normal, you have indented functions with at least two spaces and sections are then placed at a level above functions. Now, let’s take a look at how the PyPe class browser presents our CherryClass :
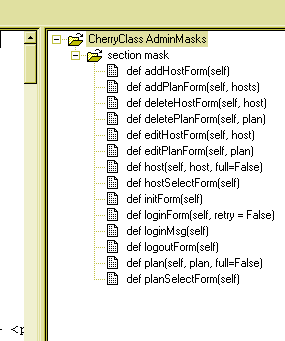
Wohoo!!!! Just what we wanted!!!
One more thing to do is to modify the file browser so it associates .cpy files with Python/CherryPy. I’ll leave this as an exercise to the reader. Look at the code at line 101 and below in configuration.py and it should be quite easy.